BigQueryの予約語を調べてもなかなか公式ドキュメントに辿り着けず悲しかったので自分のブログにリンクする
- 予約済みのキーワード
- https://cloud.google.com/bigquery/docs/reference/standard-sql/lexical?hl=ja#reserved_keywords
2023-02-08
BigQueryの予約語を調べてもなかなか公式ドキュメントに辿り着けず悲しかったので自分のブログにリンクする
2023-02-08
マジックコマンドの%%writefileを使うことでセルの内容を書き出す事ができる。
%%bash ls sample_data
%%writefile sample.txt test1 test2
%%bash ls sample_data sample.txt
%%bash cat sample.txt test1 test2
-aオプションを使うと、追記することができる
%%writefile -a sample.txt test3 Appending to sample.txt
%%bash cat sample.txt test1 test2 test3
ファイルに書き出した内容を呼び出すこともできるので、Pythonプログラムを書き出して別のノートブックから呼び出すと言ったこともできる。
%%writefile hello.py
print('Hello world')
%run hello.py Hello world
%%writefile pi.py import math print(math.pi)
%run pi.py 3.141592653589793
VS Code拡張機能のEdit CSVがとても便利だったので紹介する。
Edit CSVはVS codeの拡張機能で、CSVファイルをExcel操作のように編集することができる。
紹介ページにも、次のように書いてある。
This extensions allows you to edit csv files with an excel like table ui
CSVの拡張機能としてはRainbow CSVが有名でとても見やすくなって重宝している。一方で、一部のデータが長かったり、項目が多すぎたりすると、対応している部分がわかりづらくなってしまう面もあり、そういったときにEdit CSVが便利だった。
Edit csvをインストールした後、CSVファイルをVS Codeで開くと右上に「Edit csv」が現れる。
クリックすると、「Edit csv」でCSVファイルを開ける。
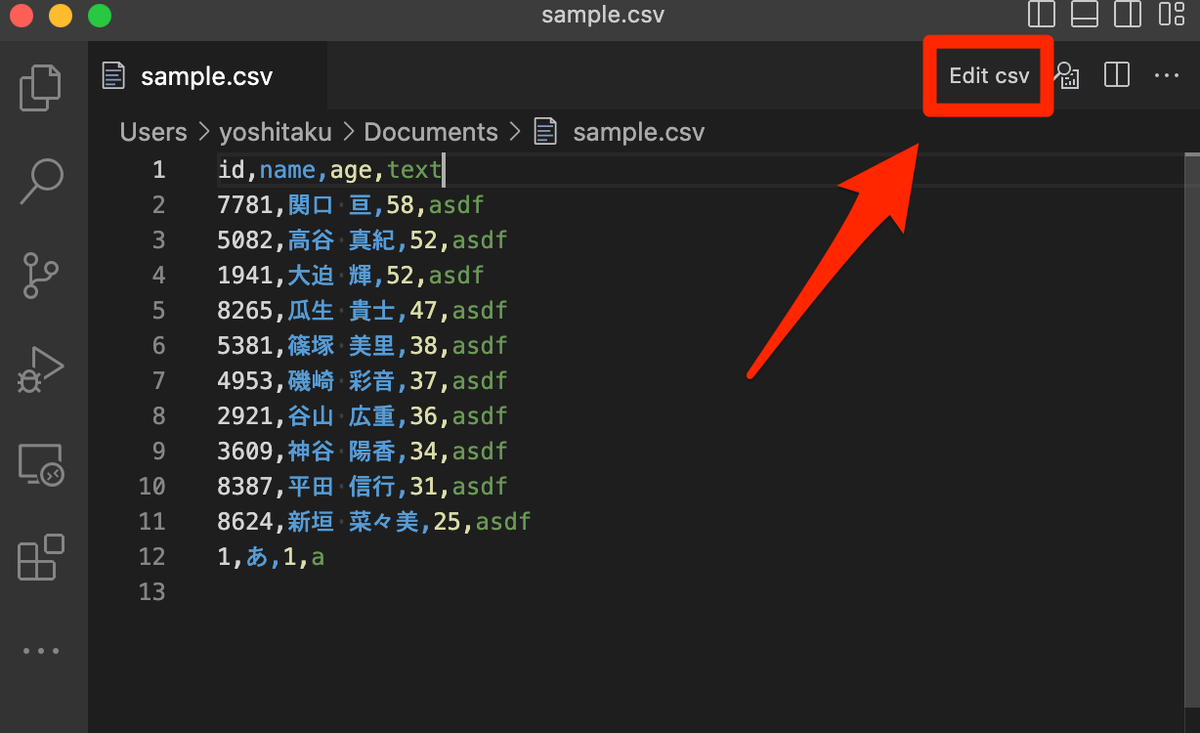
別タブが展開され、Edit csv画面でCSVファイルが開ける。
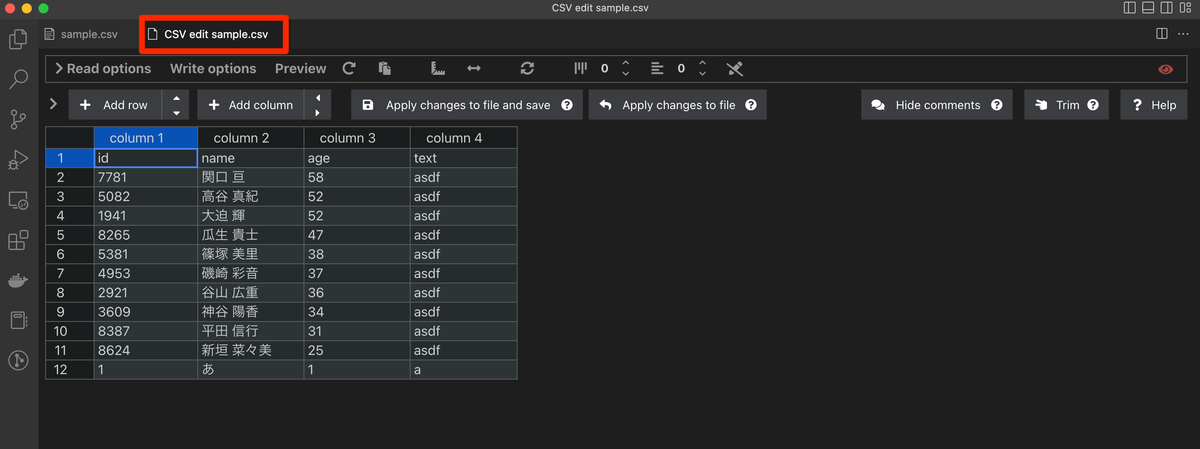
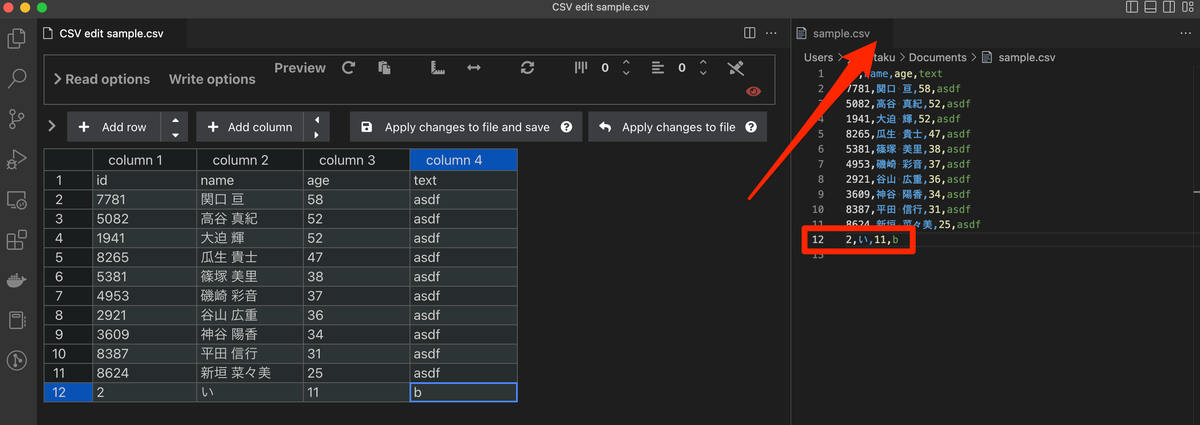
ここからは紹介ページにもあったように、ExcelのようなUIで操作ができる。12行目の値を左から順に2,い,11,bに置き換えてみた。一つ不満としては、今現在編集しているセルかどうか、どこにカーソルが合っているのかが分かりづらかったので、この部分は今後改善されると嬉しい。
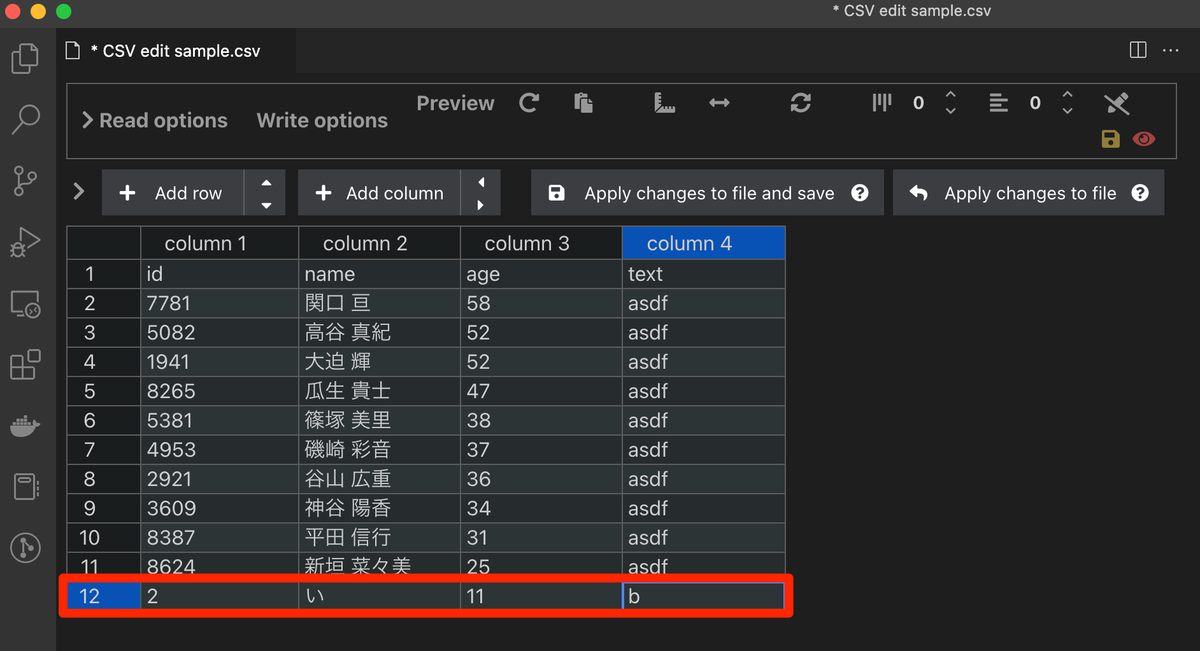
この状態は、まだ編集状態なのでCSVファイル本体へ変更を適用してみる。
CSVファイルへの反映と保存は次の2つのボタンからできる。
Apply changes to fileがファイルへの反映のみで、Apply changes to file and saveがsaveとあるように反映と保存となっている。
まずはファイルへの反映をしてみる。
2,い,11,bとなっている状態でApply changes to fileをクリックしてみる。

12行目の赤枠の値が上書きされたことがわかる。 また、赤矢印が指すようにファイルが編集中で未保存となっていることもわかる。
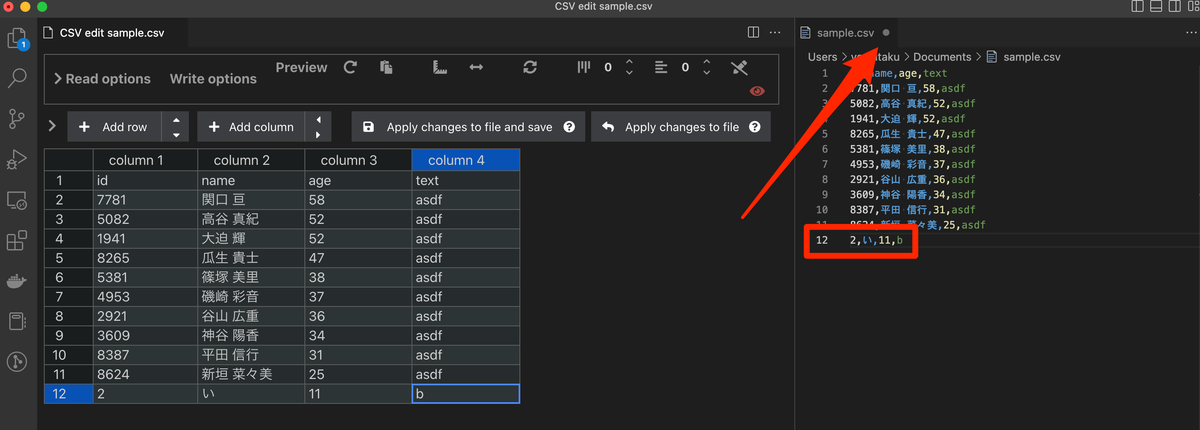
ファイルへの反映と同じことをして保存してみる。 Apply changes to file and saveをクリックすると、CSVファイルに変更が反映され、またファイルも保存されている。その証拠として、未保存時のマークが消えていることがわかる。
ExcelのようにCSVを表示してデータを編集する以外に、ヘッダー有無での読み込み、行追加、列追加などができる。
Has headerにチェックを入れると、column1-4となっていた部分が、1行目の値になる。
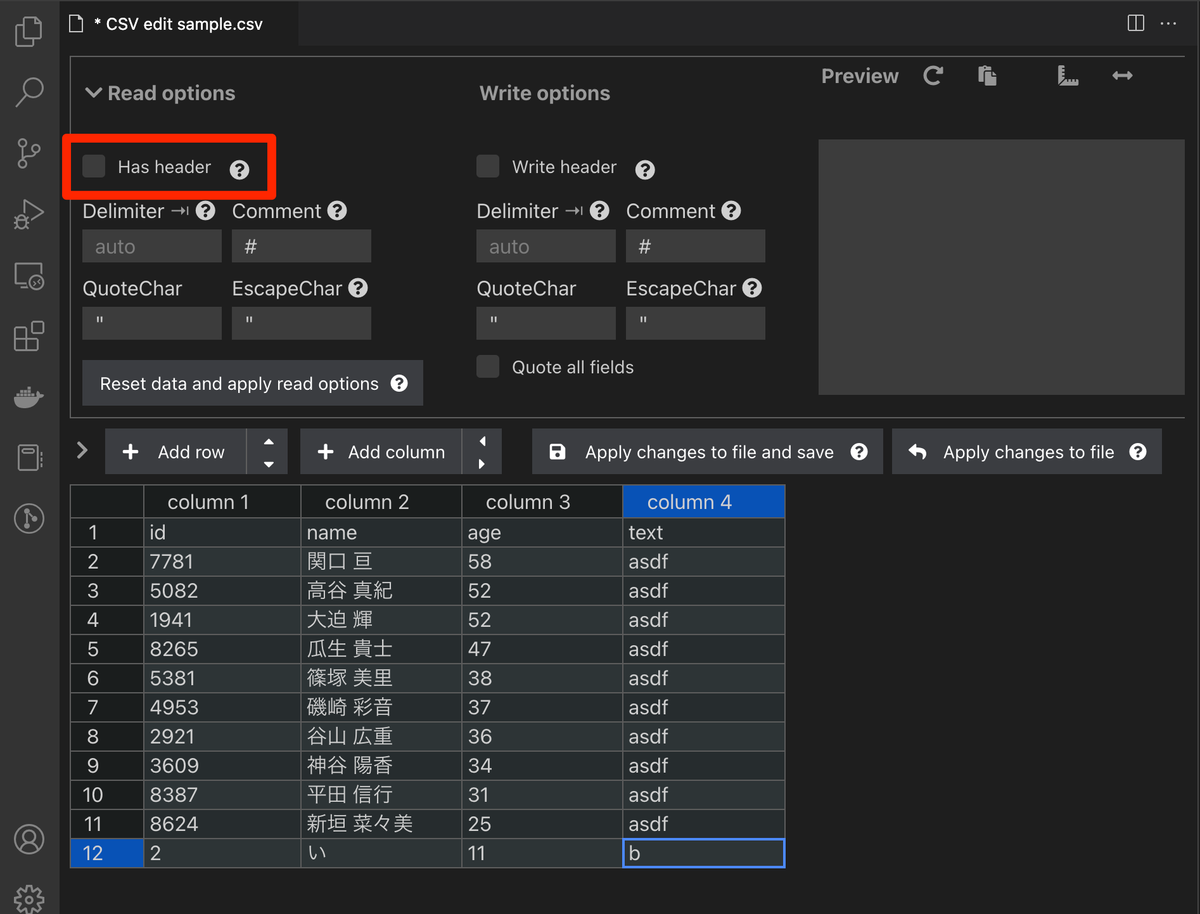
ボタンをクリックするだけで切り替わり、ファイルの再読み込みが発生しないので気持ちがいい。
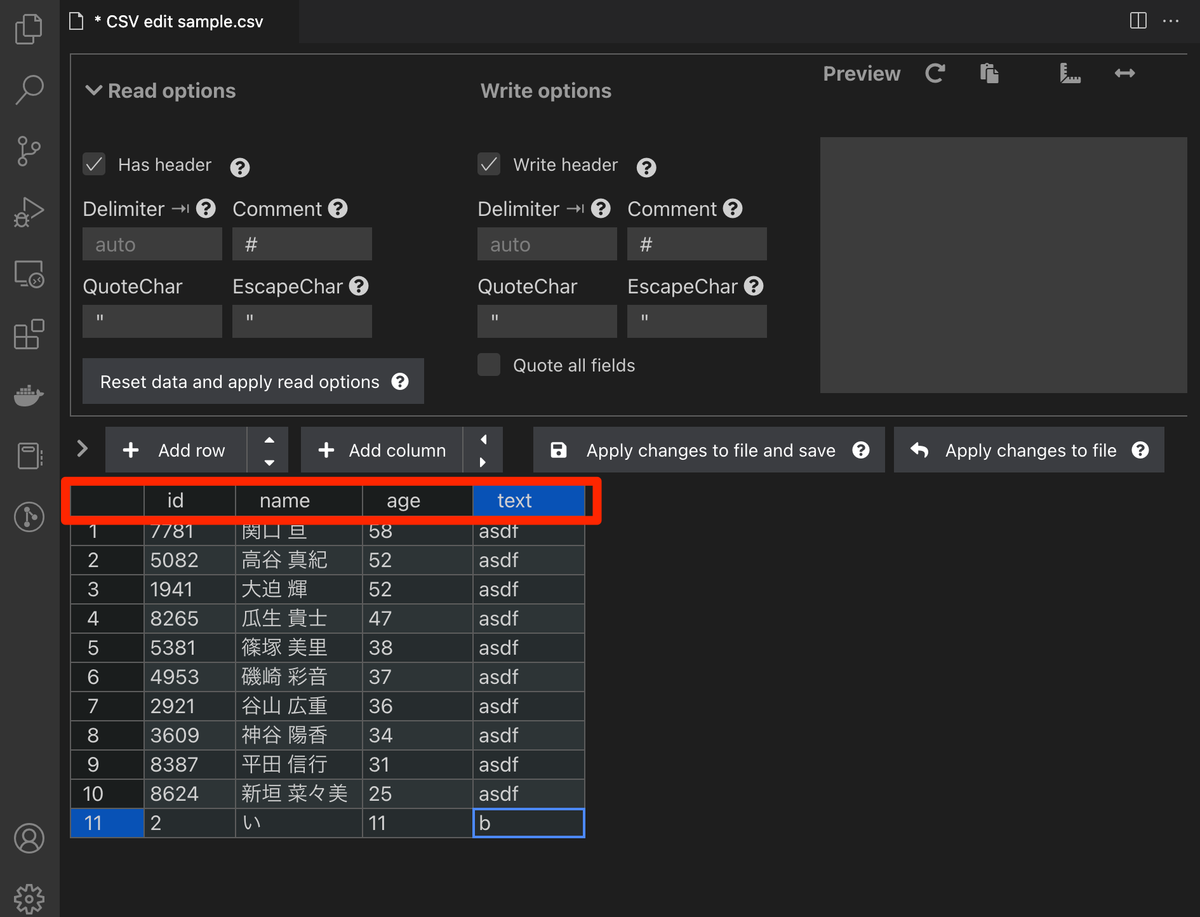
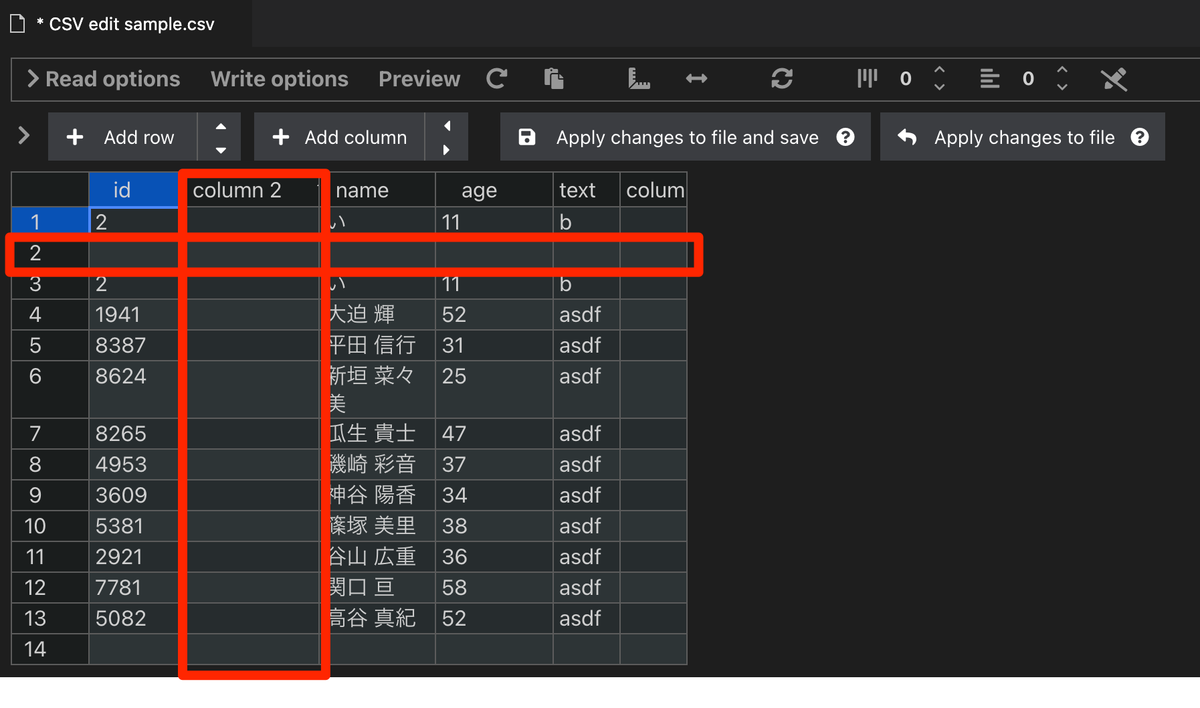
Add rowを押すと行が、Add columnを押すと列が追加される。 CSVデータへ追記したいときに便利!
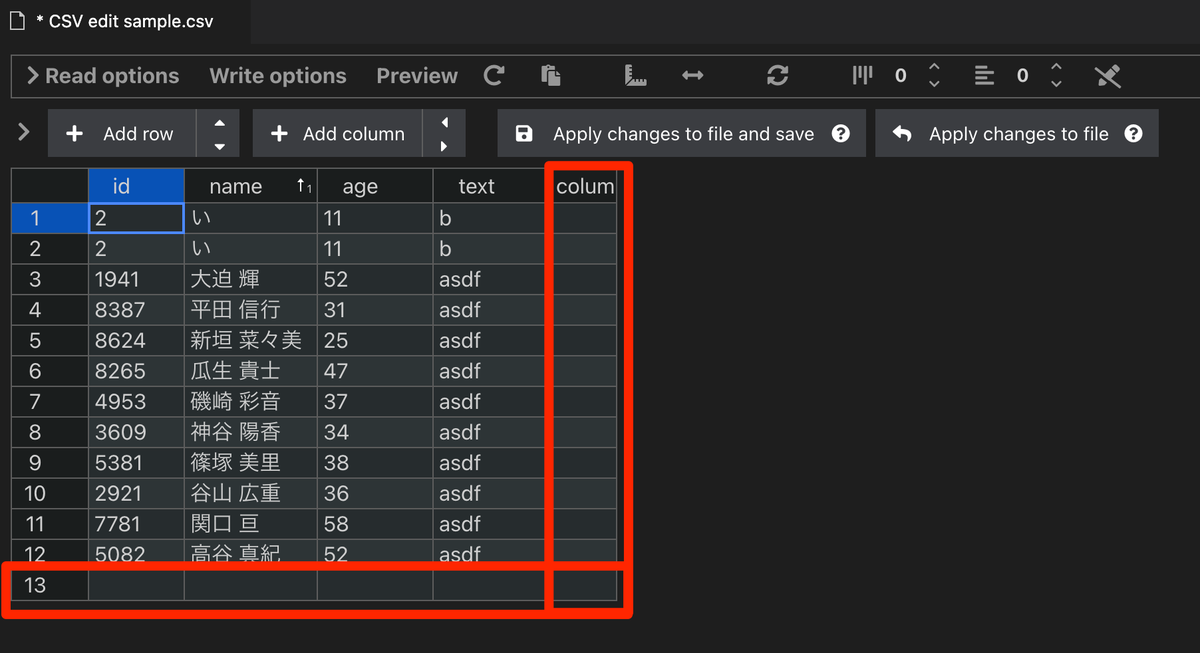
Add row / Add columnのとなりにある矢印をクリックすると、現在カーソルが合っている部分の上下、左右に1行追加することができる。下の画像ではid列の1行目にカーソルが合っている状態で下と右を押して行列を追加した。
VS Code拡張機能のEdit CSVがとても便利だったので紹介した。 VS Code上でCSVを編集するときに、とても便利だったので機会があれば試してほしい。
いまさらとなってしまったが、2022年の振り返りをする。
## 仕事
2022で自分の一番大きな変化といえば転職になる。7月までSIerでデータエンジニアの仕事をし、1ヶ月間有給消化後、9月から引き続きデータエンジニアとして事業会社で仕事をしている。
転職するきっかけとなったことがいくつかあり、前職はSIerだったため、
- 新規構築が多く、運用まで見れることが少ない
- 客先の環境なので、クラウドの権限周りなどの一歩踏み込んだ部分に手が届かない
- 社内での今後の主なキャリアアップがマネジメント活動になってしまう
といった部分があった。これらが、自分の今後のキャリアを考えた時に合っていないと感じ離れることとなった。
転職してからは、毎日を楽しく過ごせている。
初転職だったので色々戸惑うことがあると思っていたがチームメンバに支えられてここまでやってこれた。
知識の面では、SIer時代にやってきたデータ分析基盤の説明などの結果、概念的な考え方が身についていたので、現場に入ってからも構成理解に関してはスムーズだったと思う。
一方で、プログラミングやクラウドに関する部分だと、知識・技能共に足りてはいないのを如実に感じる。このあたりは日々新しいことを学べていること自体に感謝しつつ、戦力になるためにも日々研鑽しているつもりである。
## 生活周り
### 転居
転職後に引っ越しをした。転職先で出社があることもあり、始発終点で座れる場所を選んだ。飲食店も買い物に行くエリアも多く、こちらも大満足となっている。
コロナ禍で地方に移るエンジニアも多く見受けられたのでやってみたい気持ちもあったけど、自分は選択しなかった。実際に移るなら現在の状況と同じぐらいの大阪や博多あたりに住みたい。
### 英会話
転職後の話が続くが、英会話を始めた。ずっとやってみたいなと思っていたり、続かない自己学習には挑戦していたが、お金を出してスクールに通う形で続けている。今のところ、馬が合う先生に巡り会えて、その先生とプライベートレッスンを続けている。英会話を始めた理由としては、今後のキャリアを考えてのことがあった。今後データエンジニアを続けていった場合のキャリアアップとしては、
1. 現職でより大きいことをやる、それができる企業に移る
2. ベンダーに移る
3. 現職での役職を上げる
あたりが候補になると考えた。前職時代に外資のベンダーに移る人が多く、このあたりは自分にも素養がある可能性が高いと思っている。足りない部分でいうと英語になるので、今のうちに手を付けている。
現職でより大きいことをやる、それができる企業に移るに関しても、日本市場だけだと頭打ちになっていく未来が見え、結局は英語が出来て損がない未来にはなるかと思うので、今のうちにやって置きたい気持ちがあった。
もちろん結果につながればいいが、それ自体よりもいま英会話を習っていることが楽しいので、全く問題がないように思っている。
## まとめ
書く書く詐欺をしていた2022年のまとめを書いた。
正直、転職と引っ越しが大きなウェイトを締めすぎていて、他のことが霞んでしまった。それぐらい自分の中では大きいことで、この年は忘れられない年になるんだろうなと言う気がしているし、半年近く経ってもこのことを書いているので、実際にそうなんだろうなという感じである。
### と、ここまでをChatGPTに要約するよう頼んだら次のようになった
2022年に転職してデータエンジニアの仕事をしている。転職のきっかけは前職がSIerで、新規構築が多く、運用まで見れることが少ない、クラウドの権限周りなどの一歩踏み込んだ部分に手が届かない、マネジメント活動になってしまうキャリアアップしかないと感じたことが原因であった。転職後は、毎日を楽しく過ごしており、チームメンバの支えもありやってこれている。また、引っ越しをし、英会話を習得することで、今後のキャリアアップに備えている。
まとまっていてすごい。
SQL の GROUP BY を使うとカラムのデータごとに集計できる。 例えば次のようなデータがあり、GROUP BY を使って SQL を実行する。
実行環境はsqlfiddleで、MySQL5.6を使った。
データはテストデータ生成サイトで作った。 https://tm-webtools.com/Tools/TestData
野尻 成美, 48 杉江 絢子, 40 古畑 詩音, 47 沢井 金之助, 44 大前 伊都子, 22 大隅 一行, 34 今津 陽菜子, 2 東 遥華, 29 河村 一平, 35 堀川 乃愛, 57
age で GROUP BY すると次のようになり、当然だがデータごとに GROUP BY されるのでデータとしてはバラバラになる。 今回は 10 代、20 代、30 代...と、一定の範囲で GROUP BY したいときにどうするかをメモする。
SELECT age, count(*) as 人数 FROM Table1 GROUP BY age ORDER BY age;
| age | 人数 |
|---|---|
| 2 | 1 |
| 22 | 1 |
| 29 | 1 |
| 34 | 1 |
| 35 | 1 |
| 40 | 1 |
| 44 | 1 |
| 47 | 1 |
| 48 | 1 |
| 57 | 1 |
まずは CASE 文を使って分ける方法がある。 考え方含めとてもシンプルに実行できる。
SELECT
CASE
WHEN age < 10 THEN '10代以下'
WHEN age BETWEEN 10
AND 19 THEN '10代'
WHEN age BETWEEN 20
AND 29 THEN '20代'
WHEN age BETWEEN 30
AND 39 THEN '30代'
WHEN age BETWEEN 40
AND 49 THEN '40代'
WHEN age >= 50 THEN '50代以上'
ELSE NULL
END AS 年代,
count(*) as 人数
FROM
Table1
GROUP BY
CASE
WHEN age < 10 THEN '10代以下'
WHEN age BETWEEN 10
AND 19 THEN '10代'
WHEN age BETWEEN 20
AND 29 THEN '20代'
WHEN age BETWEEN 30
AND 39 THEN '30代'
WHEN age BETWEEN 40
AND 49 THEN '40代'
WHEN age >= 50 THEN '50代以上'
ELSE NULL
END
ORDER BY
age;
| 年代 | 人数 |
|---|---|
| 10 代以下 | 1 |
| 20 代 | 2 |
| 30 代 | 2 |
| 40 代 | 4 |
| 50 代以上 | 1 |
仮に年代を CASE 文で書くと、最大でも 10 代から 100 代までとなるが、もっと範囲が多いものになると辛くなる。 そういった場合は計算を使ってグループを作り出したほうが便利になる。
今回の年代のケースだと 10 の位があれば分類できるので、年齢を 10 で割り FLOOR で小数点になった 1 の位を切り落とし、GROUP BY している。
SELECT 文では# 1, CASE で分けると表記を合わせるために工夫しているが、基本的には次のようになる。
SELECT
CONCAT(
CASE
FLOOR(age / 10) * 10
WHEN 0 THEN 10
ELSE FLOOR(age / 10) * 10
END,
'代'
) AS 年代,
COUNT(*) AS 人数
FROM
Table1
GROUP BY
FLOOR(age / 10)
ORDER BY
age;
| 年代 | 人数 |
|---|---|
| 10 代 | 1 |
| 20 代 | 2 |
| 30 代 | 2 |
| 40 代 | 4 |
| 50 代 | 1 |
Python のtranslateメソッドを使うとmaketransメソッドから生成される変換表を元に文字を置換できる。
適当な文字列を作成した。日本語の文章にカンマ、ピリオドなどが入っており、これを句読点に置き換えてみる。
greeting = ''' *** おはようございます,本日は下記を対応します. - 書類提出 - ドキュメント読み込み - サンプル作成 今日も、よろしくお願いいたします. ***
*** おはようございます、本日は下記を対応します。 ・ 書類提出 ・ ドキュメント読み込み ・ サンプル作成 今日も、よろしくお願いいたします。 ***
文頭と文末に*が入っていて不要に見えるので、この置換作業の中で削除してみる。
maketransメソッドの 3 つ目の引数に指定して、削除されることも確認する。
greeting = '''
***
おはようございます,本日は下記を対応します.
- 書類提出
- ドキュメント読み込み
- サンプル作成
今日も、よろしくお願いいたします.
***
'''
print(greeting.translate(str.maketrans('.,-','。、・','*')))
おはようございます、本日は下記を対応します。 ・ 書類提出 ・ ドキュメント読み込み ・ サンプル作成 今日も、よろしくお願いいたします。
第 2 引数に#を追加すると、第 1 引数との数が一致していないのでエラーになる。
greeting = '''
***
おはようございます,本日は下記を対応します.
- 書類提出
- ドキュメント読み込み
- サンプル作成
今日も、よろしくお願いいたします.
***
'''
print(greeting.translate(str.maketrans('.,-', '。、・#', '*')))
1 greeting = '''
2 ***
3 おはようございます,本日は下記を対応します.
(...)
10 ***
11 '''
---> 13 print(greeting.translate(str.maketrans('.,-', '。、・#', '*')))
ValueError: the first two maketrans arguments must have equal length
プロジェクトの中で SQL を使い ETL 処理を書いていたが、個人によって書き方にばらつきがあり、他人の SQL を確認したりメンテナンスするタイミングがとてもつらかった。 SQL もフォーマッタや linter を使って、少しでも作業しやすくしたいと思って探していたところ、SQL Fluff に出会うことができた。 今回は SQL Fluff に入門する!
SQL Fluff は pip でインストールできる。
pip install sqlfluff
sqlfluff --versionで無事にインストールされていることを確認する。
2022/08/17 時点でのバージョンは1.2.1となっていることがわかる。
sqlfluff, version 1.2.1
チュートリアルに載っている SQL を lint してみる。
SELECT a+b AS foo, c AS bar from my_table
無事に lint が実行された!
$ sqlfluff lint test.sql --dialect ansi
== [test.sql] FAIL
L: 1 | P: 1 | L034 | Select wildcards then simple targets before calculations
| and aggregates.
L: 1 | P: 1 | L036 | Select targets should be on a new line unless there is
| only one select target.
L: 1 | P: 9 | L006 | Missing whitespace before +
L: 1 | P: 9 | L006 | Missing whitespace after +
L: 1 | P: 11 | L039 | Unnecessary whitespace found.
L: 2 | P: 1 | L003 | Expected 1 indentations, found 0 [compared to line 01]
L: 2 | P: 10 | L010 | Keywords must be consistently upper case.
All Finished 📜 🎉!
DeepL で翻訳した結果も載せておく。
計算と集計の前にワイルドカードを選択し、次に単純なターゲットを選択します。 選択対象は、選択対象が1つでない限り、改行されるべきです。 の前に空白がない の後に空白がない 不要な空白が見つかりました。 1つのインデントが予想されますが、0が見つかりました[01行目と比較して]。 キーワードは一貫して大文字でなければなりません。
指摘事項を修正して、再度 lint してみる。
SELECT
c AS bar,
a + b AS foo
FROM my_table
指摘されることがなく、無事に lint が通った!
$ sqlfluff lint test.sql --dialect ansi All Finished 📜 🎉!
Pandas で JSON の key となる部分がインデックス指向*1となっているJSONを読み込ませたい場合、read_JSON()関数にorient='index'オプションを設定すればうまくいく。
{
"0": {
"name": "Nieves Finch",
"gender": "male",
"company": "XYQAG"
},
"1": {
"name": "Frank Francis",
"gender": "male",
"company": "QUIZKA"
},
"2":{
"name": "Erna Nieves",
"gender": "female",
"company": "ISOPLEX"
}
}
orient='index'オプション無しで読み込むs = '''{
"0": {
"name": "Nieves Finch",
"gender": "male",
"company": "XYQAG"
},
"1": {
"name": "Frank Francis",
"gender": "male",
"company": "QUIZKA"
},
"2":{
"name": "Erna Nieves",
"gender": "female",
"company": "ISOPLEX"
}
}
'''
df = pd.read_json(s)
df
0,1,2 をインデックスとしたいが、name, gender, companyがインデックスになっている。
これを読み込みの段階から正しくなるようにする。
0 1 2 name Nieves Finch Frank Francis Erna Nieves gender male male female company XYQAG QUIZKA ISOPLEX
s = '''{
"0": {
"name": "Nieves Finch",
"gender": "male",
"company": "XYQAG"
},
"1": {
"name": "Frank Francis",
"gender": "male",
"company": "QUIZKA"
},
"2":{
"name": "Erna Nieves",
"gender": "female",
"company": "ISOPLEX"
}
}
'''
df = pd.read_json(s, orient='index')
df
無事に読み込む形が変わった!
name gender company 0 Nieves Finch male XYQAG 1 Frank Francis male QUIZKA 2 Erna Nieves female ISOPLEX