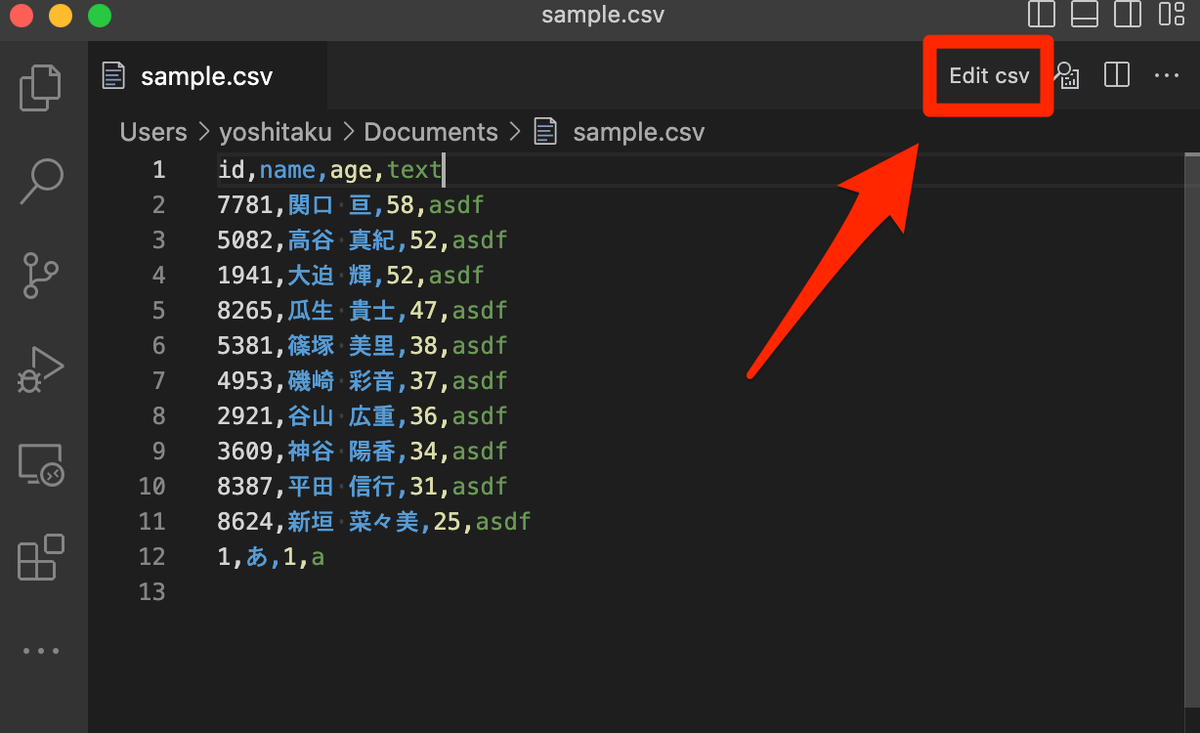
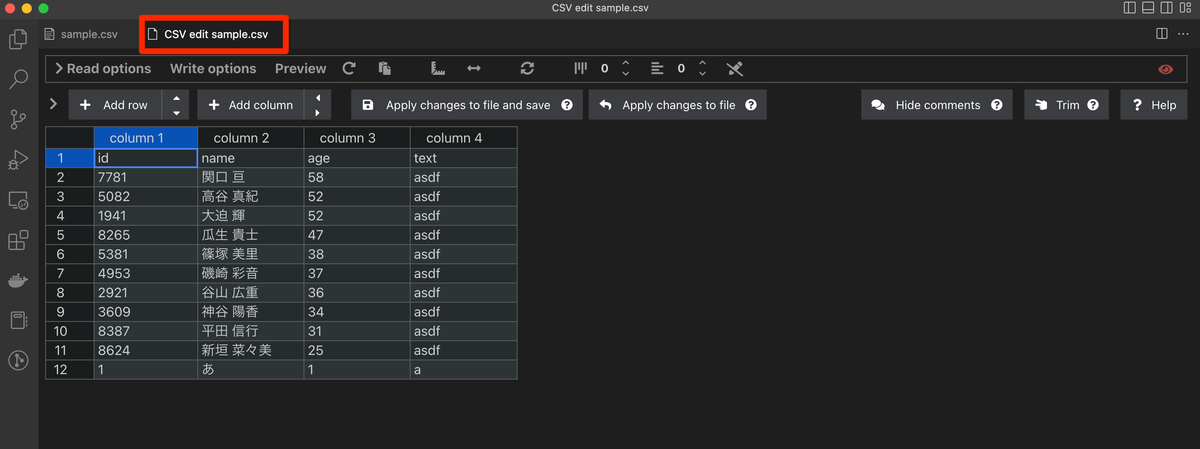
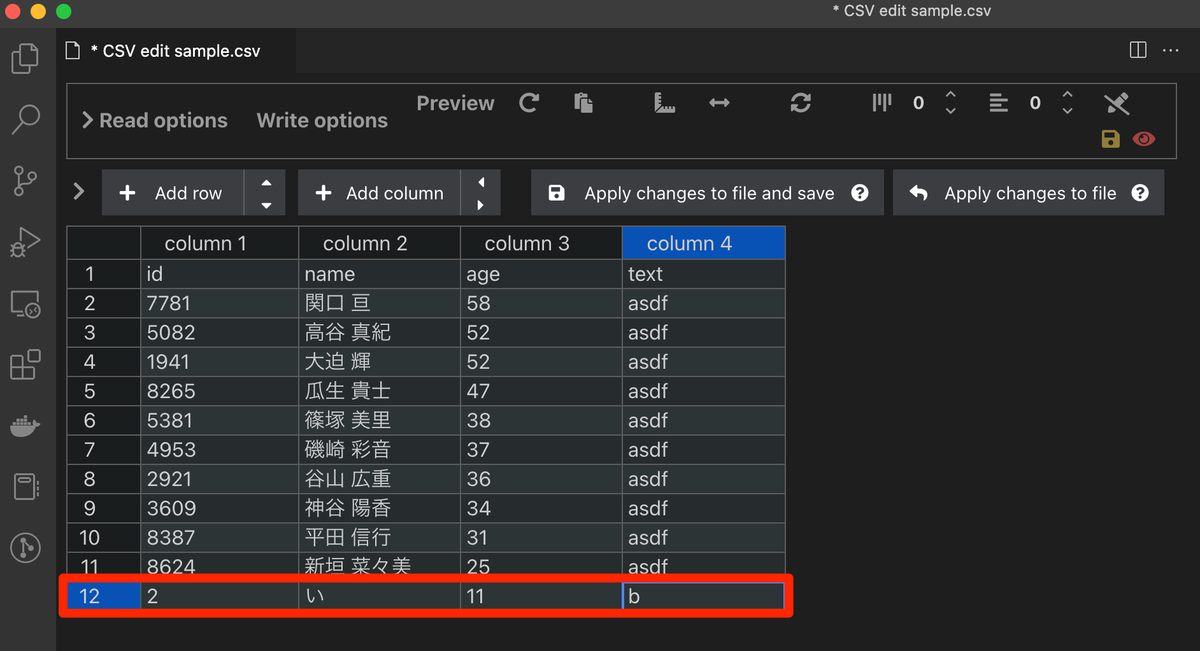
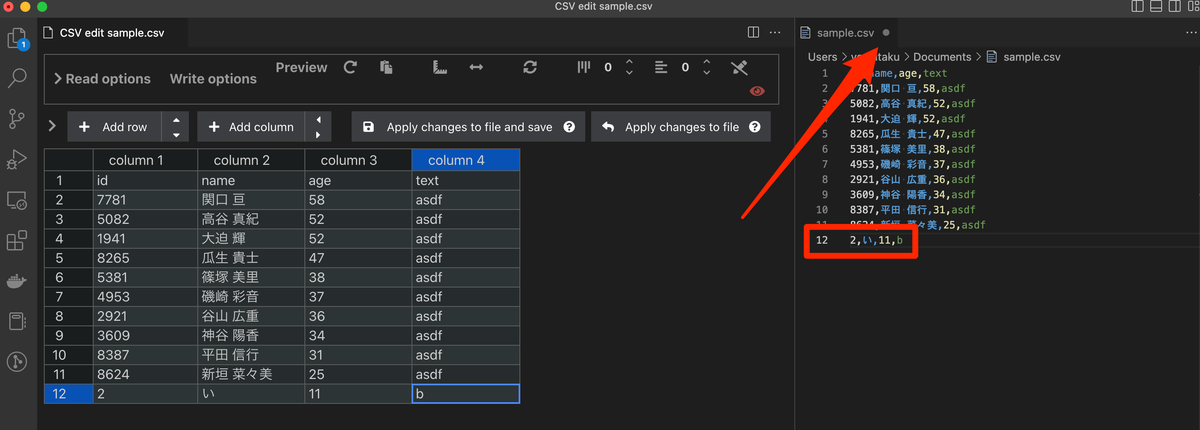
ETLツールをいろいろさわってみたいと思って、Python製のETLツールPrefectをさわってみた。
インストール
pip install prefect
バージョン確認
$ python --version Python 3.11.1 $ prefect --version 2.8.3
サンプルコード
Prefect公式で提供されている「Web APIにアクセスしてその値を返すフローとタスク」のサンプルコードを動かしてみた。 アクセス先だけは変更し、Brew Dogのビール情報を提供しているジョークのWeb APIにしてみた。
ETLのフローにはflowのデコレーターを、ETLで実際に動かしたいタスクにはtaskのデコレーターを付ける。
import requests from prefect import flow, task @task def call_api(url): response = requests.get(url) print(response.status_code) return response.json() @flow def api_flow(url): fact_json = call_api(url) return fact_json print(api_flow("https://api.punkapi.com/v2/beers/random"))
実行結果(各行の間に改行を入れた)
15:00:43.902 | INFO | prefect.engine - Created flow run 'tunneling-clam' for flow 'api-flow'
15:00:44.314 | INFO | Flow run 'tunneling-clam' - Created task run 'call_api-0' for task 'call_api'
15:00:44.316 | INFO | Flow run 'tunneling-clam' - Executing 'call_api-0' immediately...
200
15:00:45.032 | INFO | Task run 'call_api-0' - Finished in state Completed()
15:00:45.162 | INFO | Flow run 'tunneling-clam' - Finished in state
Completed()
[{'id': 284, 'name': 'Hello My Name Is Helga', 'tagline': 'Cherry Double IPA.', 'first_brewed': '2017', 'description': 'Brewed exclusively for the German market, this Hello My Name brew features a twist of flavour inspired by Germany.', 'image_url': None, 'abv': 8.2, 'ibu': 70, 'target_fg': 1009, 'target_og': 1070, 'ebc': 15, 'srm': 8, 'ph': 4.4, 'attenuation_level': 87, 'volume': {'value': 20, 'unit': 'litres'}, 'boil_volume': {'value': 25, 'unit': 'litres'}, 'method': {'mash_temp': [{'temp': {'value': 66, 'unit': 'celsius'}, 'duration': 65}], 'fermentation': {'temp': {'value': 19, 'unit': 'celsius'}}, 'twist': None}, 'ingredients': {'malt': [{'name': 'Pale Ale', 'amount': {'value': 5.52, 'unit': 'kilograms'}}, {'name': 'Caramalt', 'amount': {'value': 0.12, 'unit': 'kilograms'}}], 'hops': [{'name': 'Simcoe', 'amount': {'value': 24, 'unit': 'grams'}, 'add': '90', 'attribute': 'Bittering'}, {'name': 'Chinook', 'amount': {'value': 20, 'unit': 'grams'}, 'add': '30', 'attribute': 'Flavour'}, {'name': 'Simcoe', 'amount': {'value': 30, 'unit': 'grams'}, 'add': '0', 'attribute': 'Aroma'}, {'name': 'Citra', 'amount': {'value': 40, 'unit': 'grams'}, 'add': 'Dry Hop', 'attribute': 'Aroma'}, {'name': 'Chinook', 'amount': {'value': 40, 'unit': 'grams'}, 'add': 'Dry Hop', 'attribute': 'Aroma'}, {'name': 'Centennial', 'amount': {'value': 20, 'unit': 'grams'}, 'add': 'Dry Hop', 'attribute': 'Aroma'}, {'name': 'Simcoe', 'amount': {'value': 40, 'unit': 'grams'}, 'add': 'Dry Hop', 'attribute': 'Aroma'}], 'yeast': 'Wyeast 1272 - American Ale II™'}, 'food_pairing': ['Roast pork chops', 'Beef in port stew', 'Cherry frangipane tart'], 'brewers_tips': 'Morello Cherries are the go to cherry variety for this beer (and Krieks), the sour compliments the residual sweetness of the malt. Works well if you reduce your IBU to the 20 to 30 range too.', 'contributed_by': 'John Jenkman <johnjenkman>'}]
この数行だけで、フローとタスクが作成できたので、とてもお手軽に感じられた。
また、フローが終わったログが出た後に、return fact_jsonの中身が出力されている点は実装する上で気をつけなければいけなさそうかなと思った。
15:00:45.162 | INFO | Flow run 'tunneling-clam' - Finished in state
Completed()
-- Prefectのフローが終わったログが出ている。
-- この後に、Web APIのレスポンスであるjsonの中身が出ている。
[{'id': 284, 'name': 'Hello My Name Is Helga', 'tagline': 'Cherry Double IPA.', 'first_brewed': '2017', 'description': 'Brewed exclusively for the German market, this Hello My Name brew features a twist of flavour inspired by Germany.', 'image_url': None, 'abv': 8.2, 'ibu': 70, 'target_fg': 1009, 'target_og': 1070, 'ebc': 15, 'srm': 8, 'ph': 4.4, 'attenuation_level': 87, 'volume': {'value': 20, 'unit': 'litres'}, 'boil_volume': {'value': 25, 'unit': 'litres'}, 'method': {'mash_temp': [{'temp': {'value': 66, 'unit': 'celsius'}, 'duration': 65}], 'fermentation': {'temp': {'value': 19, 'unit': 'celsius'}}, 'twist': None}, 'ingredients': {'malt': [{'name': 'Pale Ale', 'amount': {'value': 5.52, 'unit': 'kilograms'}}, {'name': 'Caramalt', 'amount': {'value': 0.12, 'unit': 'kilograms'}}], 'hops': [{'name': 'Simcoe', 'amount': {'value': 24, 'unit': 'grams'}, 'add': '90', 'attribute': 'Bittering'}, {'name': 'Chinook', 'amount': {'value': 20, 'unit': 'grams'}, 'add': '30', 'attribute': 'Flavour'}, {'name': 'Simcoe', 'amount': {'value': 30, 'unit': 'grams'}, 'add': '0', 'attribute': 'Aroma'}, {'name': 'Citra', 'amount': {'value': 40, 'unit': 'grams'}, 'add': 'Dry Hop', 'attribute': 'Aroma'}, {'name': 'Chinook', 'amount': {'value': 40, 'unit': 'grams'}, 'add': 'Dry Hop', 'attribute': 'Aroma'}, {'name': 'Centennial', 'amount': {'value': 20, 'unit': 'grams'}, 'add': 'Dry Hop', 'attribute': 'Aroma'}, {'name': 'Simcoe', 'amount': {'value': 40, 'unit': 'grams'}, 'add': 'Dry Hop', 'attribute': 'Aroma'}], 'yeast': 'Wyeast 1272 - American Ale II™'}, 'food_pairing': ['Roast pork chops', 'Beef in port stew', 'Cherry frangipane tart'], 'brewers_tips': 'Morello Cherries are the go to cherry variety for this beer (and Krieks), the sour compliments the residual sweetness of the malt. Works well if you reduce your IBU to the 20 to 30 range too.', 'contributed_by': 'John Jenkman <johnjenkman>'}]