
はじめに
社内でもくもく会を開催してみました。何を取り扱うか1つ決めておこう!となったときに、
- BI製品を扱っている会社なのでBI製品が良い
- ちゃんと資料が作成されているものがいい
と言う話が上がり、@ariarijpさんと@kakakakakkuさんが作成・講師をしてくださったRedashハンズオンを思い出しました。そして、今回はこれを社内メンバ数人でもくもく作業してみることにしました!自分はRedashハンズオン参加したこともあり、今回の社内もくもく会では講師・サポーターの立ち回りで動きました。
資料に関しては最高のものなので、再度メンバーを増やして開催する際や、別の方がやる際に参考になればとメンバが詰まったところを記載しておきます。
実際の作業で詰まったところ
Windows端末にdockerをインストールすることに手こずる
RedashハンズオンはDockerを使って作業を進めていきます。今回集まってくれた方の中には、Dockerがインストールされていない人もいたので、windows端末にDockerをインストールする作業からはじめました。「Dockerってどんなもの?」という質問も出ましたので、技術書典で購入した「マンガでわかるDocker」を読んでもらったりしてイメージを掴んでもらいました。(「他の仮想環境と技術的にどう違うのか」という質問も出たので、これはいつかまとめてちゃんと説明できるようにしておきます………)
Redashハンズオンの部分ではないのですが、一番詰まった点はwindows端末にDockerをインストールする点でした。Virtualizationが有効になっていなかったりで、BIOSをいじったりしました。キャプチャがないので追記します。
[Docker] Docker For Windowsをセットアップしてみた (Docker初心者向け)
docker-compose upがうまくいかない
docker-compose upした後に、Redashがうまく立ち上がらないことがありました。。(自分はWindows環境ではないのでエラーログのキャプチャがないのですが、後で共有してもらい貼っておきます。)原因はホスト側の端末でポート80を既に使っているために起こったもののようです。普段から開発している端末でハンズオンをおこなったので、まっさらなWindows端末でやっても同じことが起きるのでしょうか…調査が必要かも?またハンズオンを開催する際に同じことが起きるか見ておきます。今回は2/2人の確率で起きてしまったので、Windowsの方は注意が必要だと思います。
解決方法としては、docker-composeファイルのnginxのportsの"80:80"を"8081:80"にして、再度docker-compose upを叩きます。
# This is an example configuration for Docker Compose. Make sure to atleast update
# the cookie secret & postgres database password.
#
# Some other recommendations:
# 1. To persist Postgres data, assign it a volume host location.
# 2. Split the worker service to adhoc workers and scheduled queries workers.
version: '2'
services:
server:
image: redash/redash:4.0.1.b4038
command: server
depends_on:
- postgres
- redis
ports:
- "5000:5000"
environment:
PYTHONUNBUFFERED: 0
REDASH_LOG_LEVEL: "INFO"
REDASH_REDIS_URL: "redis://redis:6379/0"
REDASH_DATABASE_URL: "postgresql://postgres@postgres/postgres"
REDASH_COOKIE_SECRET: veryverysecret
REDASH_WEB_WORKERS: 4
worker:
image: redash/redash:4.0.1.b4038
command: scheduler
environment:
PYTHONUNBUFFERED: 0
REDASH_LOG_LEVEL: "INFO"
REDASH_REDIS_URL: "redis://redis:6379/0"
REDASH_DATABASE_URL: "postgresql://postgres@postgres/postgres"
QUEUES: "queries,scheduled_queries,celery"
WORKERS_COUNT: 2
REDASH_HOST: "http://localhost"
redis:
image: redis:3.0-alpine
postgres:
image: postgres:9.5.6-alpine
# volumes:
# - /opt/postgres-data:/var/lib/postgresql/data
nginx:
image: redash/nginx:latest
ports:
#- "80:80" ←ここを変えます
- "8081:80" #←これに変えます
depends_on:
- server
links:
- server:redash
mysql:
image: kakakakakku/mysql-57-world-database
environment:
MYSQL_ALLOW_EMPTY_PASSWORD: "yes"
TZ: Japan
うまく起動することができたら資料に記載にあるhttp://localhostではなく、http://localhost:8081をブラウザでアクセスすると、Redashのログイン画面に行くことができました。
データソース設定が反映されない
RedashからMysqlのデータソースに接続できるように、設定をおこないます。しかし、画像のように右下にSuccessを緑で何回も表示されても、データソースにMysqlが表示されない事象がありました。
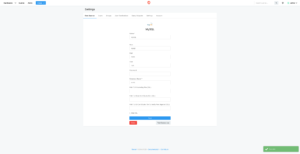
画像はhttps://github.com/kakakakakku/redash-hands-on/blob/master/images/data_source.pngより
原因はIEで動かしていたことでした。Chromeで再度Redashにアクセスしたところ大量に保存されたMysqlデータソースが発見されました(笑)。業務アプリケーションをIEで動かすことが多く、今回もRedashをIEで動かしていたようです。
Redashの公式サイトを確認したところ「We recommend using Chrome or Firefox.」という記載があったので、同様の事象があったときはどのブラウザを使っているか確認する必要、もしくは推奨どおりに「Chrome or Firefox」を使うことを最初にアナウンスしておくのがいいかと思います。
参考:https://redash.io/help/faq/general/
Browsers Redash Works Best
On We recommend using Chrome or Firefox.
If you encounter any issues that are browser specific, please let us know.
まとめ
今回は社内もくもく会でRedashのハンズオンをおこないました。
個人的に良かった点は3つほどあります。
1. 講師・サポーターの動きが学べた
2. 自分の知識整理になった
3. 社内でのコミュニケーションが生まれた
もくもく会なので、もくもく別の作業する人もいましたし、提案したRedashのハンズオンに参加していただけたりもして良かったです。
自分としては、社内なので圧倒的ホーム感の中でしたが、講師・サポーターの動きが学べて良かったです!!もっと他の人の学びやサポートに貢献していきたいと思いました。
質問をされたことによって、自分の知識の整理にもなった点も非常に良かったです!!
もくもく会が終わった後に飲み会をしましたが、その場でも活発にコミュニケーションが生まれて良かったです。とあるアプリケーションを使うときにリレーショナルデータベースとNoSQLどちらを使うべきかとか、自分が学んだ知識をすぐ活かせることができた点も印象に残っています。
yoshitaku-jp.hatenablog.com
以上です!


")










{kind=link}